- SVM(Support Vector Machine):支持向量机
- SVC(Support Vector Classifier):支持向量分类器
- SVR(Support Vector Regression):支持向量回归器
支持向量机基本型
给定大小为 m 的训练集 D={(x1,y1),(x2,y2),…,(xm,ym)},yi∈{−1,1}。基于训练集 D 在样本空间中找到一个超平面,将不同类别的样本分开,如下图:

明显红色的划分超平面更合适。划分超平面可通过线性方程描述:
wTx+b=0
- w=(w1,w2,…,wn):为法向量,决定了超平面的方向;
- b:位移项。
- x=(x1,x2,…,xn)
样本空间中任意点到超平面 (w,b) 的距离为:
r=∣∣w∣∣∣wTx+b∣
在做分类时,应有 (xi,yi)∈D,当 yi=+1 时,wTxi+b>0;当 yi=−1 时,wTxi+b<0。令:
{wTxi+b≥+1,yi=+1wTxi+b≤−1,yi=−1
距离超平面最近的几个训练样本点满足上式,如下图 H1、H2 上的样本被称为支持向量(support vector)。
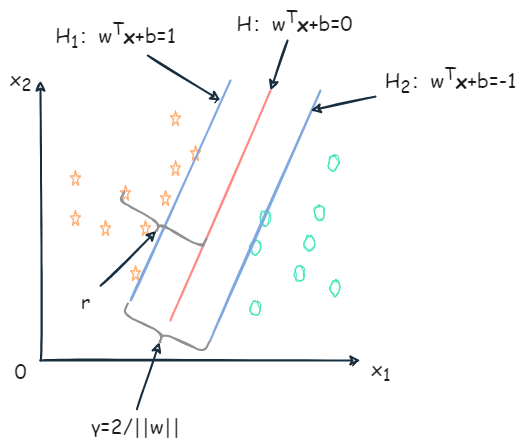
两个异类的支持向量到超平面的距离之和(也称为间隔)为:
γ=∣∣w∣∣∣(b+1)−(b−1)∣=∣∣w∣∣2
为了找到具有最大间隔的划分超平面,需要满足下式中约束参数 w 和b,使得 γ 最大:
w,bmax∣∣w∣∣2同时保证 yi(wTxi+b)≥1,i=1,2,…,m.
为了最大化间隔,需要最大化 ∣∣w∣∣−1,等价于最小化 ∣∣w∣∣2
w,bmin21∣∣w∣∣2同时保证 yi(wTxi+b)≥1,i=1,2,…,m.
对上式使用拉格朗日乘子法可得到它的对偶问题。
-
拉格朗日乘⼦法是⼀种寻找多元函数在⼀组约束下的极值的方法。
- 通过引⼊拉格朗日乘子,可将有 d 个变量与 k 个约束条件的最优化问题转化为具有 d+k 个变量的⽆约束优化问题求解。
-
对上式每条约束添加拉格朗日乘子 αi≥0
-
对偶问题是原始问题的一种变换形式,它在数学上与原始问题密切相关,但可能具有不同的结构和性质。
L(w,b,α)=21∣∣w∣∣2+i=1∑mαi(1−yi(wTxi+b))
- 其中 α=(α1,α2,…,αm)
令 L(w,b,α) 对 w 和 b 的偏导为零,可得
∂w∂L(w,b,α)=w−i=1∑mαiyixi=0⇒w=i=1∑mαiyixi
∂b∂L(w,b,α)=−i=1∑mαiyi=0⇒0=i=1∑mαiyi
将 w=∑i=1mαiyixi 代入 L(w,b,α),将 w 和 b 消去,再结合 0=∑i=1mαiyi,得到 minw,b21∣∣w∣∣2 的对偶问题:
αmaxi=1∑mαi−21i=1∑mj=1∑mαiαjyiyjxiTxj(1)
同时保证 i=1∑mαiyi=0,αi≥0,i=1,2,…,m.
求解出 α 后:
f(x)=wTx+b=i=1∑mαiyixiTx+b(2)
上述过程需满足 KKT 条件,即:
⎩⎪⎪⎨⎪⎪⎧αi≥0yif(x)−1≥0αi(yif(x)−1)=0
对任意训练样本 (xi,yi),总有 αi=0 或 yif(xi)=1。
- 若 αi=0,该样本不会出现在式 1 的求和中,也不会对 f(xi) 产生影响。
- 若 αi>0,则必有 yif(xi)=1,对应的样本点位于最大间隔边界上,即支持向量。
训练完后,大部分训练样本也不需要保留,最终模型仅与支持向量有关。
SMO
对于式 1 的求解,可以使用二次规划算法求解,也可以通过 SMO(Sequential Minimal Optimization) 算法求解。
SMO 的基本思路:
核函数
上述讨论训练样本是线性可分的(即存在划分超平面能正确分类),如果原始样本空间内不能存在这样的划分超平面,那么需要 将样本从原始空间映射到更高维的空间,使其在这个特征空间内线性可分。
- 令 ϕ(x) 表示将 x 映射后的特征向量,则在特征空间中划分超平面所对应的模型表示为:
f(x)=wTϕ(x)+b
其中 w 和 b 为模型参数,有:
w,bmin21∣∣w∣∣2同时保证 yi(wTϕ(xi)+b)≥1, i=1,2,…,m
其对偶问题是:
αmaxi=1∑mαi−21i=1∑mj=1∑mαiαjyiyjϕ(xi)Tϕ(xj)同时保证 i=1∑mαiyi=0,αi≥0,i=1,2,…,m
设计核函数:
κ(xi,xj)=<ϕ(xi),ϕ(xj)>=ϕ(xi)Tϕ(xj)
- 即 xi 与 xj 在特征空间的内积等于它们在原始样本空间通过函数 κ(⋅,⋅) 计算的结果。
所以之前的式子改写为:
αmaxi=1∑mαi−21i=1∑mj=1∑mαiαjyiyjκ(xi,xj)同时保证 i=1∑mαiyi=0,αi≥0,i=1,2,…,m
求解后可得到:
f(x)=wTϕ(x)+b=i=1∑mαiyiϕ(xi)Tϕ(x)+b=i=1∑mαiyiκ(xi,x)+b
- 上式说明模型最优解可通过训练样本的核函数展开,展式称为支持向量展式。
定理:令 χ 为输入空间,κ(⋅,⋅) 式定义在 χ×χ 上的对称函数,则 κ 式核函数 当且仅当 对于任意数据 D={x1,x2,…,xm},核矩阵 K 总是半正定的:
K=⎣⎢⎢⎢⎢⎢⎢⎢⎡κ(x1,x1)⋮κ(xi,x1)⋮κ(xm,x1)⋯⋱⋯⋱⋯κ(x1,xj)⋮κ(xi,xj)⋮κ(xm,xj)⋯⋱⋯⋱⋯κ(x1,xm)⋮κ(xi,xm)⋮κ(xm,xm)⎦⎥⎥⎥⎥⎥⎥⎥⎤
- 对于一个半正定和矩阵,总能找到一个与之对应的映射 ϕ。任何一个核函数都隐式定义了一个称为“再生核希尔伯特空间”(简称RKHS)的特征空间。
常用核函数如下:
- 线性核:κ(xi,xj)=xiTxj;
- 多项式核:κ(xi,xj)=(xiTxj)d,d≥1 为多项式的次数;
- 高斯核:κ(xi,xj)=exp(−2σ2∣∣xi−xj∣∣2),σ>0 为高斯核的带宽;
- 拉普拉斯核:κ(xi,xj)=exp(−σ2∣∣xi−xj∣∣2),σ>0;
- Sigmoid核:κ(xi,xj)=tanh(βxiTxj+θ),tanh 为双曲正切函数,β>0,θ<0。
此外,核函数还可通过组合得到:
- 若 κ1 和 κ2 为核函数,则对于任意正数 γ1、γ2,其线性组合 γ1κ1+γ2κ2 也是核函数。
- 若 κ1 和 κ2 为核函数,则核函数的直积 κ1⊗κ2(xi,z)=κ1(xi,z)κ2(xi,z) 也是核函数。
- 若 κ1 为核函数,则对于任意函数 g(x),κ(x,z)=g(x)κ1(x,z)g(z) 也是核函数。
C-SVC算法
C-SVC算法:受参数 C 的制约。
- 参数 C 是最小的训练误差和最大的分类间隔的折中。
- 常用交叉验证法选取 C。
给定大小为 m 的训练集 D,其中每个样本具有 n 个属性,对应一个标签 yi∈{+1,−1} 表示其分类。
超平面方程表示为:
wTx+b=0
对每一个样本 xi,引入一个松弛变量 ξ≥0,作为错误分类误差的度量,可以被认为是在分类错误的情况下样本与属于它的间隔边界超平面的距离。
ξi={0,1−yi(wTxi+b),如果 yi(wTxi+b)≥+1如果 yi(wTxi+b)≤+1
由上式得到原公式下实现软间隔最大化的约束条件:
yi(wTxi+b)≥1−ξi, ξi≥0, i=1,2,…,m
如下图 H1 和 H2 之间的间隔称为软间隔:

在软间隔最大化中,被软间隔分隔错误的样本应该受到惩罚,且随着 ξi 增大而增加。还要尽可能减少错误分隔的样本数。软间隔最大化原公式如下:
min21∣∣w∣∣2+Ci=1∑mξi同时保证 yi(wTxi+b)≥1−ξi, ξi≥0,i=1,2,…,m
- C 为非负的惩罚参数,用于对分类错误样本的一定程度上的惩罚。
- C 大,相当于错误惩罚力度大。达到一定程度从而没有错误分类的样本,软间隔最大化等价于硬间隔最大化。
- C 小,相当于错误惩罚力度小。可能有更多样本被软间隔分类错误。
- ∑i=1mξi 为分类错误的总量。
对其进行构造拉格朗日方程:
L(w,b,α,ξ,μ)=21∣∣w∣∣2+i=1∑mαi(1−yi(wTxi+b))+i=1∑m(C−αi−μi)ξi
也求偏导得到
∂w∂L(w,b,α,ξ,μ)=w−i=1∑mαiyixi=0⇒w=i=1∑mαiyixi
∂b∂L(w,b,α,ξ,μ)=−i=1∑mαiyi=0⇒0=i=1∑mαiyi
∂ξi∂L(w,b,α,ξ,μ)=C−αi−μi=0
最后通过偏导式、拉格朗日方程、原公式得到软间隔对偶优化问题:
αmax−21i=1∑mj=1∑mαiαjyiyjxiTxj+i=1∑mαi同时保证 i=1∑mαiyi=0和0≤αi≤C, i=1,2,…,m
KTT 条件:
αi(yi(wTxi+b)−1+ξi)=0, (C−αi)ξi=0, i=1,2,…,m
- ξi=0, αi=0:样本被正确分类,并且这些样本不是支持向量,不影响最终解。
- ξi=0, 0<αi<C:样本在间隔超平面上,即这些向量是支持向量。
- 0<ξi≤1, αi=C:表示样本被分割超平面正确分类,但落在软间隔内。
- ξi>1, αi=C:样本被错误分类。
设 α∗=(α1∗,α2∗,…,αm∗) 为解,得到分隔超平面的法向量 w∗ 为:
w∗=i=1∑mαi∗yixi
然后通过 αi(yi(wTxi+b)−1+ξi)=0, (C−αi)ξi=0, i=1,2,…,m 计算 b,并把它的平均值作为分隔超平面的偏移量 b∗,则最终的决策函数为:
f(x)=sgn(i=1∑mαi∗yiK(xi⋅x)+b∗)
ν-SVC 算法
使用参数 ν 代替参数 C。
- 表示支持向量占全部训练样本的比例下限;
- 也表示错误分类样本占全部训练样本的比例上限。
- 如 ν=0.05,则保证最多有5%的训练样本被错分类,且至少有5%的支持向量。
用常系数 ν 代替参数 C,同时还引入一个需要被优化的变量 ρ,ν-SVC 的原公式:
min21∣∣w∣∣2−νρ+m1i=1∑mξi同时保证 yi(wTxi+b)≥ρ−ξi和ξi≥0,ρ≥0,i=1,2,…,m
ν-SVC 的软间隔宽度为:2ρ/∣∣w∣∣。
拉格朗日方程:
L(w,b,α,ξ,μ,ρ,δ)=21∣∣w∣∣2−νρ+m1i=1∑mξi−i=1∑mα[yi(wTxi+b)−ρ+ξi]−i=1∑mμξi−δρ
再次求偏导,使导数为0,得到:
w=i=1∑mαiyixi
αi+μi=m1
i=1∑mαiyi=0
i=1∑mαi−δ=0
结合,最终得到二次优化问题:
αmax−21i=1∑mj=1∑mαiαjyiyjK(xi,xj)同时保证 i=1∑mαiyi=0,0≤αi≤m1和i=1∑mαi≥ν, i=1,2,…,m
常系数 ν 仍需满足:
ν≤m2min(Nums(yi=+1),Nums(yi=−1))
- Nums(yi=+1) 表示样本中正例数量。
- Nums(yi=−1) 表示样本中负例数量。
决策函数为:
f(x)=sgn(i=1∑mαi∗yiK(xi,x)+b∗)
w=i=1∑mαiyixi
设两个集合 S+ 和 S−,集合内分别为正例和负例的支持向量(ξi=0),元素数量都为 s。约束变成 yif(xi)=ρ。得到 b∗ 和 ρ∗:
b∗=−2s1x∈S+∪S−∑i=1∑mαi∗yiK(x,xi)
ρ∗=2s1⎝⎜⎛x∈S+∑i=1∑mαi∗yiK(x,xi)−x∈S−∑i=1∑mαi∗yiK(x,xi)⎠⎟⎞
多类问题的 SVC
处理多类问题时,把多个类转化为若干个问题处理。
一对其余:用一类与其余类进行比较。
- 如将类1作为正例,其他组合一起作为负例,得到决策函数 f1(x);然后将类2作为正例,其余组合一起作为负例,得到决策函数 f2(x)。以此类推得到 k 个决策函数。
- 当对新样本 x,带入下式得到分类:
argimaxfi(x)
一对一:一共得到 k(k−1)/2 个决策函数 fi,j(x),0≤i<j≤k,表示第 i 类和第 j 类比较得到的决策函数。
- 当对新样本 x,需要代入所有的 fi,j(x),统计所有类别的胜出次数,得票最多的类即为结果。
单类 SVM
单类问题并不是进行分类,而是判断新样本是否属于该类。
如判断银行业务中是否为欺诈交易时,无法提供足够多的欺诈例子用于训练,但有大量正常交易用于建模。
解决方法:Tax & Duin 法和 Schölkopf 法。
Tax & Duin 法:在输入空间或特征空间内找到一个体积最小的超球体,能够包含全部训练样本。
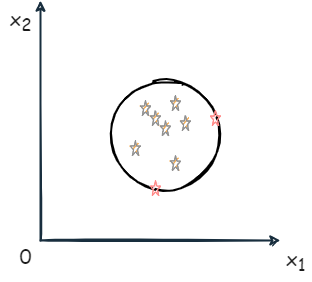
- 当然也为每个样本 xi 分配一个松弛变量 ξi
带有 ξi、球心为 a、半径为 R 的超球体表达式为:
F(R,a,ξi)=R2+Ci=1∑mξi
- C 是常数,用于平衡超球体的体积大小和超球体外样本的数量。
使得上式最小化,还需满足约束:
∣∣ϕ(xi)−a∣∣2≤R2+ξi,ξi≥0,i=1,2,…,m
- ϕ(xi) 表示样本 xi 从输入空间到特征空间的映射。
拉格朗日乘子法得到:
L(R,a,α,ξ,μ)=R2+Ci=1∑mξi−i=1∑mαi[R2+ξi−∣∣ϕ(xi)−a∣∣2]−i=1∑mμiξi
- αi 和 μi 都不小于0。
基于变量 R、a、ξi 的偏导数分别为:
i=1∑mαi=1
a=i=1∑mαiϕ(xi)
C−αi−μi=0
通过代入得到对偶公式:
L(R,a,α,ξ,μ)=i=1∑mαiϕ(xi)⋅ϕ(xi)−i=1∑mj=1∑mαiαjϕ(xi)⋅ϕ(xj)
使用核函数代替点乘,得到二次优化问题:
αmaxi=1∑mαiK(xi,xi)−i=1∑mj=1∑mαiαjK(xi,xj)受限于i=1∑mαi=1, 0≤αi≤C,i=1,2,…,m
在超球体表面的样本为支持向量。
- 超球体的半径 R 可通过计算球心 a 到任意一个支持向量的距离得到。
设解为 α∗=(α1∗,α2∗,⋯+αm∗),支持向量为 xs :
R2=∣∣ϕ(xj)−a∣∣∣2=∣∣ϕ(xs)−i=1∑mαi∗ϕ(xi)2∣∣=K(xs,xs)−2i=1∑mαi∗K(xs,xs)+i=1∑mj=1∑mαi∗αj∗K(xi,xj)
当判断样本是否属于该类时,需要计算样本 x 与球心的距离 a,并与半径 R 比较,如果小于半径,则是该类,否则不属于该类。
决策函数:
f(x)=sgn(d(x))
f(x)=sgn(R2−K(x,x)+2i=1∑mαi∗K(xi,x)−i=1∑mj=1∑mαi∗αj∗K(xi,xj))=sgn(K(xs,xs)−K(x,x)−2i=1∑mαi∗[K(xi,xs)−K(xi,x)])
- xs 表示任意一个支持向量;
- 当 f(x)=1,表示 x 属于该类。
Schölkopf 法:在特征空间找到一个超平面,该超平面能够分隔全部样本和坐标原点,并且要使该超平面到远点的距离最远。

求解:
min21∣∣w∣∣2+νm1i=1∑mξi−ρ受限于 (w⋅ϕ(xi))≥ρ−ξi,ξi≥0,i=1,2,…,m
- ν 表示支持向量占全部训练样本的比例下限,也表示错误分类样本占全部训练样本的比例上限。
做拉格朗日方程:
L(w,ξ,ρ,α,μ)=21∣∣w∣∣2+νm1i=1∑mξi−ρ−i=1∑mαi(w⋅ϕ(xi)−ρ+ξi)−i=1∑mμiξi
对 w、ξ、ρ 求偏导,使其为0,有:
w=i=1∑mαiϕ(xi)
αi=νm1−μi⇒αi≤νm1
i=1∑mαi=1
则对偶问题为:
αmax−21i=1∑mj=1∑mαiαiK(xi,xj)受限于 i=1∑mαi=1,0≤αi≤νm1,i=1,2,…,m
设解为 α∗=(α1∗,α2∗,⋯,αm∗),若 αi 和 μi 都不为0,则 ξi 必为0:
ρ=(w⋅ϕ(xs))
- xs 为任意一个支持向量。
由 αj 不为0,代入 w=∑i=1mαiϕ(xi),则:
ρ=(w⋅ϕ(xs))=i=1∑mαiK(xi,xs)
决策函数:
f(x)=sgn(d(x))=sgn((w⋅ϕ(x))−ρ)
f(x)=sgn(i=1∑mαi∗K(xi,x)−i=1∑mαi∗K(xi,xs))
- xs 为任意一个支持向量。
- x 为待预测样本。
- 当 f(x)=1,表示 x 属于该类。
ε-SVR 算法
Vapnik 通过 ε 不敏感损失函数,把 SVM 扩展到回归问题中。
设 yi 为样本 x 对应的响应值,回归问题则是找到一个函数 f(x),使得 f(xi)=yi。
Lossε={0,∣y−f(x)∣−ε,如果∣y−f(x)≤ε其他
- ε>0,表示控制误差限度的常量,即如果误差在 [−ε,ε] 之间,就认为忽略误差。
线性关系时,函数表示为:
f(x)=w⋅x+b

由于误差允许,所以在 f(x) 周围形成一个包围,称之为 ε 管。
ε-SVR 中,得到 f(x) 还需要满足:
- 使 f(x) 与测量值 yi 的偏差值不大于 ε,让所有样本都在 ε 管中。
- 使 f(x) 尽可能平坦,简化模型,能够避免过拟合。平直指的是样本中各个特征属性对样本贡献大小应该均衡,即 w 要小。
ε-SVR 问题表示为:
min21∣∣w∣∣2受限于{yi−w⋅xi−b≤εw⋅xi+b−yi≤ε,i=1,2,…,m
也使用软间隔,引入两个松弛变量 ξ+ 和 ξ−,上式改写为:
- ξi+ 表示那些被高估的样本响应值的误差;
- ξi− 表示那些被低估的样本响应值的误差
min21∣∣w∣∣2+Ci=1∑m(ξi++ξi−)受限于{yi−w⋅xi−b≤ε+ξi−w⋅xi+b−yi≤ε+ξi+, {ξi−≥0ξi+≥0, i=1,2,…,m
- C>0:为常数,均衡 f(x) 的平坦程度与偏差大于 ε 的样本数量。
∣ξ∣ε={0,∣ξ∣−ε,如果∣ξ∣≤ε其他
表示改写后的拉格朗日乘子法方程为:
L(w,b,ξ,α,μ)=21∣∣w∣∣2+Ci=1∑m(ξi++ξi−)−i=1∑m(μi+ξi++μi−ξi−)−i=1∑mαi+(ε+ξi++yi−w⋅xi−b)−i=1∑mαi−(ε+ξi−−yi+w⋅xi+b)
- αi+、αi−、μi+、μi− 都为非负值。
对原变量 w、b、ξ 进行求偏导并使其为0:
∂w∂L=w−i=1∑m(αi−−αi+)xi=0⇒w=i=1∑m(αi−−αi+)xi
∂b∂L=i=1∑m(αi+−αi−)=0
∂ξ+∂L=C−μi+−αi+=0
∂ξ−∂L=C−μi−−αi−=0
进入代入,得到对偶优化问题:
α−,α+max−21i=1∑mj=1∑m(αi−−αi+)(αj−−αj+)K(xi,xj)−εi=1∑m(αi−+αi+)+i=1∑myi(αi−−αi+)受限于 i=1∑m(αi−−αi+)=0, αi−,αj+∈[0,C]
- K(xi,xj):为核函数,同前映射关系。
设解为 α∗=(α1−∗,α1+∗,⋯,αm−∗,αm+∗),则:
w=i=1∑m(αi−∗−αi+∗)ϕ(xi)
最后回归计算公式:
f(x)=i=1∑m(αi−∗−αi+∗)K(xi,x)+b∗
由 KKT 条件计算:
b∗=yj−i=1∑m(αi−∗−αi+∗)K(xi,xj)+ε
或
b∗=yk−i=1∑m(αi−∗−αi+∗)K(xi,xk)−ε
- (xj,yj) 为任意一个样本对应的 αj+∗∈(0,C);
- (xk,yk) 为任意一个样本对应的 αk−∗∈(0,C)。
由 KKT 条件,还可以知道 αi−∗ 或 αi+∗ 等于 C 的样本在 ε 管外,而且 αi−∗ 或 αi+∗ 不可能同时为0。
这意味着一个样本不能拥有两个方向的松弛变量 ξ,只能向一个方向偏离。
ν-SVR 算法
Schölkopf 从 ν-SVC 算法上扩展得到 ν-SVR 算法。
ν-SVR 原公式:
min21∣∣w∣∣2+C(νε+m1i=1∑m(ξi++ξi−))受限于 {yi−w⋅ϕ(xi)−b≤ε+ξi−w⋅ϕ(xi)+b−yi≤ε+ξi+, {ξi−≥0ξi+≥0, i=1,2,…,m
ε-SVR 中,参数 ε 通过经验选取,而在 ν-SVR 中把 ε 作为目标函数的一个变量。同时 C 和 ν 为常数, C 为正值; ν∈[0,1] 同样表示支持向量占全部训练样本的比例下限,也表示错误估计样本占全部训练样本的比例上限。
取拉格朗日方程为:
L(w,b,β,ε,ξ,α,μ)=21+Cνε+mCi=1∑m(ξi++ξi−)−βε−i=1∑m(μi+ξi++μi−ξi−)−i=1∑mαi+(ε+ξi++yi−w⋅ϕ(xi)−b)−i=1∑mαi−(ε+ξi−−yi+w⋅ϕ(xi)+b)
对原变量 w、ε、b、ξ 求偏导并使之为0:
∂w∂L=w−i=1∑m(αi−−αi+)ϕ(xi)=0⇒w=i=1∑m(αi−−αi+)ϕ(xi)
∂ε∂L=Cν−i=1∑m(αi++αi−)−β=0
∂b∂L=i=1∑m(αi+−αi−)=0
∂ξ+∂L=mC−μi+−αi+=0
∂ξ−∂L=mC−μi−−αi−=−β
进入代入,得到对偶优化问题:
α−,α+max−21i=1∑mj=1∑m(αi−−αi+)(αj−−αj+)K(xi,xj)+i=1∑myi(αi−−αi+)受限于 i=1∑m(αi−−αi+)=0, αi−,αj+∈[0,mC], i=1∑m(αi++αi−)≤Cν
设解为 α∗=(α1−∗,α1+∗,⋯,αm−∗,αm+∗),则最后回归计算公式:
f(x)=i=1∑m(αi−∗−αi+∗)K(xi,x)+b∗
由 KKT 条件得到:
b∗=21[yi+yk−i=1∑m(αi−∗−αi+∗)K(xi,xj)−i=1∑m(αi−∗−αi+∗)K(xi,xk)]
- (xj,yj) 为任意一个样本对应的 αj+∗∈(0,C/N);
- (xk,yk) 为任意一个样本对应的 αk−∗∈(0,C/N)
解 ε∗ 为:
ε∗=i=1∑m(αi−−αi+)K(xi,xj)−yj+b∗
或
ε∗=yk−i=1∑m(αi−−αi+)K(xi,xj)−b∗
- (xj,yj) 为任意一个样本对应的 αj+∗∈(0,C/N);
- (xk,yk) 为任意一个样本对应的 αk−∗∈(0,C/N)
OpenCV所支持的 SVM
OpenCV 提供了五种支持向量机的类型,分别为:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
| enum Types {
C_SVC=100,
NU_SVC=101,
ONE_CLASS=102,
EPS_SVR=103,
NU_SVR=104
};
|
通过 SVM::setType(int val) 设置 SVM 类型,默认为 C_SVC。通过 SVM::getType() 获取 SVM 类型。
各个类型的 SVM 的超参可以通过以下函数访问:
- C:通过
SVM::setC(double val) 和 SVM::getC() 访问。
- ν:通过
SVM::setNu(double val) 和 SVM::getNu() 访问。
- ε:通过
SVM::setP(double val) 和 SVM::getP() 访问。
同时支持的核函数有:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
| enum KernelTypes {
CUSTOM=-1,
LINEAR=0,
POLY=1,
RBF=2,
SIGMOID=3,
CHI2=4,
INTER=5
};
|
使用 SVM::setKernelType(int kernelType) 设置核函数类型。
- 多项式核为:K(xi,xj)=(γxiTxj+coef0)degree, γ>0
- 径向基函数 RBF:K(xi,xj)=e−γ∣∣xi−xj∣∣2, γ>0
- Sigmoid 函数:K(xi,xj)=tanh(γxiTxj+coef0)
- 指数 CHI2 核:K(xi,xj)=e−γχ2(xi,xj), χ2(xi,xj)=(xi−xj)2/(xi+xj), γ>0
- 直方图相交核:K(xi,xj)=min(xi,xj)
上述的超参:
- γ:通过
SVM::setGamma(double val) 和 SVM::getGamma() 访问。
- coef0:通过
SVM::setCoef0(double val) 和 SVM::getCoef0() 访问。
- degree:通过
SVM::setDegree(int val) 和 SVM::getDegree() 访问。
关于迭代设置函数:setTermCriteria(const cv::TermCriteria &val):
- 该类变量需要3个参数:类型、迭代的最大次数、特定的阈值。
- 类型:迭代的最大次数
TermCriteria::MAX_ITER 、特定的阈值(期望精度) TermCriteria::EPS 或 MAX_ITER + EPS。
还有关于 SVM::trainAuto(...),函数如下:
1
2
3
4
5
6
7
8
| bool trainAuto( const Ptr<TrainData>& data, int kFold = 10,
ParamGrid Cgrid = getDefaultGrid(C),
ParamGrid gammaGrid = getDefaultGrid(GAMMA),
ParamGrid pGrid = getDefaultGrid(P),
ParamGrid nuGrid = getDefaultGrid(NU),
ParamGrid coeffGrid = getDefaultGrid(COEF),
ParamGrid degreeGrid = getDefaultGrid(DEGREE),
bool balanced=false) = 0;
|
- 该方法通过选择最佳参数 C、γ、p、ν、coef0、degree 来自动训练 SVM 模型。当测试集误差的交叉验证估计值最小时,参数被认为是最佳的。
- 如果不需要优化参数,则应将相应的网格步长设置为小于或等于1的任何值。
data:训练集;kFold:交叉验证参数。训练集被划分为kFold子集。一个子集用于测试模型,其他子集形成训练集;Cgrid:参数 C 的网格;gammaGrid:参数 γ 的网格;pGrid:参数 ε 的网格;nuGrid:参数 ν 的网格;coeffGrid:参数 coef0 的网格;degreeGrid:参数 degree 的网格;balanced:如果为真且问题是 2 分类,则该方法创建更平衡的交叉验证子集,即子集中的类之间的比例接近整个训练数据集中的比例。
类似地,该函数重载还有:
1
2
3
4
5
6
7
8
9
10
11
| bool trainAuto(InputArray samples,
int layout,
InputArray responses,
int kFold = 10,
Ptr<ParamGrid> Cgrid = SVM::getDefaultGridPtr(SVM::C),
Ptr<ParamGrid> gammaGrid = SVM::getDefaultGridPtr(SVM::GAMMA),
Ptr<ParamGrid> pGrid = SVM::getDefaultGridPtr(SVM::P),
Ptr<ParamGrid> nuGrid = SVM::getDefaultGridPtr(SVM::NU),
Ptr<ParamGrid> coeffGrid = SVM::getDefaultGridPtr(SVM::COEF),
Ptr<ParamGrid> degreeGrid = SVM::getDefaultGridPtr(SVM::DEGREE),
bool balanced=false) = 0;
|
例子-香蕉数据集
数据集地址:https://sci2s.ugr.es/keel/dataset.php?cod=182
该数据集十分简单,只有两个属性和一个标签。
- 属性
At1 和 At2:分别对应于x轴和y轴的两个属性。
- 标签
-1 和 +1:表示数据集中的两种香蕉形状之一。
部分数据如下表:
| At1 |
At2 |
Class |
| 0.174 |
1.92 |
-1.0 |
| 1.64 |
0.0477 |
-1.0 |
| -0.478 |
-0.796 |
-1.0 |
| -0.447 |
-1.0 |
-1.0 |
| -1.04 |
-0.2 |
1.0 |
| 2.06 |
-0.482 |
-1.0 |
使用 OpenCV 提供的 SVM 模型效果如下:
1
2
3
4
5
| Train Data imported: 5100
Test Data imported: 200
SVM算法(基于OpenCV实现):
计算花费时长:131ms
正确率:0.915
|
代码地址:Gitee - SVM