神经网络是一种模仿生物神经系统的机器学习算法。
神经元
人工神经网络由若干个神经元构成。神经元结构如下:

- x1、x2、...、xn 是神经元的输入。
- y 是神经元的输出。
- w1、w2、...、wn 是神经元的权重。
- b 为偏移量。
神经元内部包括两个部分:
- 输入的加权求和;
u=i=1∑n(wixi)+b=i=0∑n(wixi),x0恒为1
- 对求和结果的“激活”。激活指的是对输出值进行某种关系映射,使得神经元兴奋或抑制。
y=f(u)
激活函数有多种:
线性函数:
f(x)=x
阈值函数:
f(x)={1,0,x≥θx<θ
Sigmoid 函数:
f(x)=1+e−x1
对称 Sigmoid 函数:
f(x)=β1+e−αx1−e−αx
双曲正切函数:
f(x)=ex+e−xex−e−x
高斯函数:
f(x)=βe−α2x2
RELU 函数:
f(x)=max(0,x)
感知器
感知器由两层神经元组成:
感知器的学习规则很简单,对于训练样本 (x,y),若当前感知机输出为 y^,则权重调整为:
wi=wi+Δwi=wiη(y−y^)xi
- η∈(0,1) 称为学习率。
感知器只有输出层神经元进行激活函数处理,也就是只有一层功能神经元,处理线性可分问题。
- 存在一个线性超平面将样本分开,则感知器的学习过程会收敛。
多层感知器 MLP
解决非线性可分问题,需要考虑多层(功能)神经元。
前馈神经网络是神经网络的一种,包括一个输入层、一个输出层和若干个隐含层。
- 某一层的神经元只能通过一个方向连接到下一层的神经元。
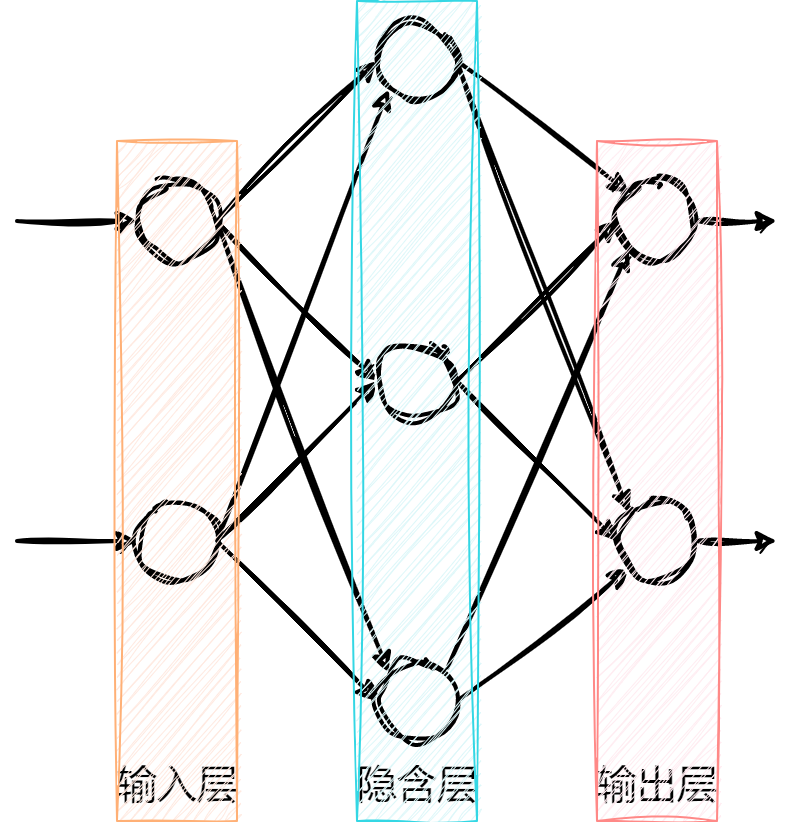
像上图这种拓扑结构的神经网络又称为多层感知器(MLP,Multi-Layer Perceptron)。
MLP 可以用 Backprop(backward propagation of errors,误差反向传播,BP)算法实现建模。
BP 算法输入层的神经元数量一般为样本的特征属性数量,输出层的神经元的数量一般为样本的所有可能目标值的数量。
BP 算法的核心思想是:通过前向通路得到误差,再把误差反向传播,实现权值的修正。
MPL 的误差可以用平方误差函数表示。
- 设某个样本 x=(x1,x2,...,xn) 对应的目标值为 t,有 J 种可能值,t={t1,t2,...,tj}。
- 则 MLP 输入层一共有 n 个神经元,输出层(第 L 层)有 J 个神经元。
设样本 x 经过前向通路得到的最终输出为 y={y1L,y2L,...,yjL}。
则该样本的平方误差为:
E=21j=1∑J(tj−yjL)2
- 21 为方便求导系数,不影响误差的变化趋势。
MLP 的目标是使得 E 最小。通过改变权值 w,从而使得 E 最小。
Backprop算法是一种迭代的方法,渐进地减小 E。
误差 E 对权值 w 的导数为 w 的变化率:
Δw=−ηdwdE
- η∈(0,1) 表示学习效率,控制收敛速度和准确性。
- η 过大,导致震荡,很难收敛;
- η 过小,导致长时间不能收敛。
引入“动量” μ,改变因 η 的选取不好而带来的问题,上式改写为:
Δw(t)=−ηdwdE(t)+μΔw(t−1)
- t 表示当前,t−1 表示上一次,t+1 表示下一次。
- 说明本次的 w 变化率不仅与 E 的导数相关,还与上一次 w 的变化率相关。
- μ 提供了一些惯性,使之平滑权值的随机波动。
由 Δw 更新当前权值 w:
w(t+1)=w(t)+Δw(t)
- 上式表示了更新权值的过程是从输出层到隐含层,向输入层逐层推进的过程,即误差的反向传播。
当所有权值更新完后,再由前向通路计算得到新的误差 E,完成一次迭代。
具体计算过程
设 wkhl 表示第 l 层的第 k 个神经元与第 l−1 层的第 h 和神经元之间连接的权值。第 l 层的第 k 个神经元的输出 ykl 为:
ykl=f(ukl)=f(h=1∑H(wkhlyhl−1)+bkl)
- ukl 表示第 l 层第 k 个神经元的加权和;
- bkl 表示第 l 层第 k 个神经元的偏置。
若第 l 层共有 K 个神经元,第 l−1 层共有 H 个神经元,则第 l 层的 K 个神经元的加权和 ul 可以用矩阵表示:
ul=⎝⎜⎜⎜⎜⎛u1lu2l⋮uKl⎠⎟⎟⎟⎟⎞=⎝⎜⎜⎜⎜⎛w11lw21l⋮wK1lw12lw22l⋮wK2l⋯⋯⋱⋯w1Hlw2Hl⋮wKHl⎠⎟⎟⎟⎟⎞⎝⎜⎜⎜⎜⎛y1l−1y2l−1⋮yHl−1⎠⎟⎟⎟⎟⎞+⎝⎜⎜⎜⎜⎛b1lb2l⋮bKl⎠⎟⎟⎟⎟⎞
第 l 层的所有 K 个神经元输出 yl 为:
yl=⎝⎜⎜⎜⎜⎛y1ly2l⋮yKl⎠⎟⎟⎟⎟⎞=⎝⎜⎜⎜⎜⎛f(u1l)f(u2l)⋮f(uKl)⎠⎟⎟⎟⎟⎞=f(ul)
把每层的输出 yl 级联在一起,就构成了 MLP 的前向通路。
- 当一个样本添加到输入层时,通过层层计算得到最终输出 yL,再代入误差计算中得到误差。
前向通路过程为,样本进行权值计算,通过激活输出,最后得到误差:
wkhl→ukl→ykl→E
计算权值变化率,即对误差求导,由链式法则可知,样本 x 的误差 E 对权值 wkhl 的偏导数为:
∂wkhl∂E=∂ykl∂E∂ukl∂ykl∂wkhl∂ukl
- 定义 δkl 为上式等号右侧的前两项偏导,δkl=∂ykl∂E∂ukl∂ykl=∂ukl∂E
计算上式等号右侧第三个偏导,有:
∂wkhl∂ukl=∂wkhl∂[h=1∑H(wkhlyhl−1)+bkl]∂wkhl∂ukl=∂wkhl∂(wk1ly1l−1+⋯+wkhlyhl−1+⋯+wkHlyHl−1+bkl)∂wkhl∂ukl=yhl−1
- 求导的结果为第 l−1 层的第 h 个神经元的输出。如果第 l−1 为输入层,则 yhl−1 为样本的第 h 个属性。
计算上式等号右侧第二个偏导,有:
∂ukl∂ykl=∂ukl∂f(ukl)=f′(ukl)
- f(⋅) 表示激活函数。
- 线性函数求导为:dxdf(x)=dxdx=1。
- Sigmoid 函数求导为:dxdf(x)=dxd(1+e−x1)=1+e−x1(1−1+e−x1)=f(x)(1−f(x))
- 对称 Sigmoid 函数求导为: dxdf(x)=dxd(β1+e−αx1−e−αx)=2αβ(1+e−αx)2e−αx
- 双曲正切函数求导为:dxdf(x)=dxd(ex+e−xex−e−x)=1−f2(x)
- 高斯函数求导为: dxdf(x)=dxd(βe−α2x2)=−2α2βxe−α2x2
计算上式等号右侧第一个偏导,当 ykl 为输出层的输出时,即 yjL,有:
∂yjL∂E=∂yjL∂[21j=1∑J(tj−yjL)2]∂yjL∂E=∂yjL∂[21(t1−y1L)2+⋯+21(tj−yjL)2+⋯+21(tJ−yJL)2]∂yjL∂E=yjL−tj
所以,基于输出层的权值 yjhL 误差导数为:
∂wjhL∂E=(yjL−tj)f′(ujL)yhL−1
- δjL=(yjL−tj)f′(ujL)
不知道内部神经元的输出误差,只知道输出层的误差,所以需要把内部神经元误差传递到输出层。
- 又因为神经元都直接或间接地相互连接,所以内部所有神经元的误差最终都会传递到输出层的所有神经元上。
设 yhl 为中间第 l 层的第 h 个神经元的输出,则:
∂yhl∂E=∂yhl∂[E(u1l+1),⋯,E(uKl+1)]
- E(ukl+1) 表示误差 E 是关于 ukl+1 的函数。
上式表明,第 l 层的第 h 个神经元的输出误差传递到第 l+1 层内的所有 K 个神经元内,则:
∂yhl∂E=k=1∑K(∂ukl+1∂E∂yhl∂ukl+1)
计算右侧第二个偏导:
∂yhl∂ukl+1=∂yhl∂[h=1∑H(wkhl+1yhl)+bkl+1]∂yhl∂ukl+1=∂yhl∂(wk1l+1y1l+⋯+wkhl+1yhl+⋯+wkHl+1yHl+bkl+1)∂yhl∂ukl+1=wkhl+1
计算右侧第一个偏导:
∂ukl+1∂E=δkl+1
所以,基于中间层的权值 wkhl 的误差导数为:
∂wkhl∂Ep=[k=1∑K(wkhl+1δkl+1)]f′(ukl)yhl−1
先得到输出层的结果,再计算倒数第二层,以此类推,完整的误差导数:
∂wkhl∂E=δklyhl−1,其中δkl={(ykl−tk)f′(ukl),[∑k=1K(wkhl+1δkl+1)]f′(ukl),l为输出层l为中间层
把上式的结果代入计算得到 权值的变化率。再由 w(t+1)=w(t)+Δw(t) 得到更新后的权值。经过新权值计算下一样本,反复进行。
计算的方法:
- 在线方法:样本一个一个地进入 MLP,每完成一个样本的计算,就更新一次权值。
- 为了增加鲁棒性,每次迭代之前,可以把全体样本打乱顺序,这样在每次迭代的过程中,提取样本的顺序就会不相同。
- 批量方法:把所有样本的误差累加在一起,用该累加误差计算误差的导数,进而得到权值的变化率。
初始化权值
一般会随机选择很小的值作为初始权值。
采用 Nguyen-Widrow 算法初始化权值:
- 每个神经元都有属于自己的一个区间范围,通过初始化权值就可以限制它的区间位置。当改变权值时,也在自己的区间范围内变化。
Nguyen-Widrow 算法初始化 MLP 权值的方法为:
- 对于所有连接输出层的权值和偏移量,初始值为在 −1 到 1 之间的随机数;
- 对于中间层的权值,初始化为(νh 为 −1 到 1 之间的随机数,H 为第 l−1 层神经元的数量):
wkhl=∑h=1H∣νh∣νh
- 对于中间层的偏移量,初始化为(νk 为 −1 到 1 之间的随机数,K 为第 l 层神经元的数量):
bkl=(K2k−1)νkG
G=0.7HK−11
RPROP
上述 BP 算法的权值变化基于误差梯度的变化率。
而 RPROP 算法的权值变化基于它的符号:
Δw(t)=⎩⎪⎪⎨⎪⎪⎧−Δ(t),+Δ(t),0,∂w∂E(t)>0∂w∂E(t)<0其他
其中,
Δ(t)=⎩⎪⎪⎨⎪⎪⎧η+Δ(t−1),η−Δ(t−1),Δ(t−1),∂w∂E(t−1)∂w∂E(t)>0∂w∂E(t−1)∂w∂E(t)<0其他
- 常数 η+ 必须大于1;
- 常数 η− 必须在0~1之间。
- ∂E/∂w 由下式得到:
∂wkhl∂E=δklyhl−1,其中δkl={(ykl−tk)f′(ukl),[∑k=1K(wkhl+1δkl+1)]f′(ukl),l为输出层l为中间层
- Δ(0)=0.1 比较好;
- Δmax(t)=50,Δmin(t)=10−6 可以防止溢出。
OpenCV 提供的 ANN
OpenCV 提供的神经网络算法有:
1
2
3
4
5
6
| enum TrainingMethods
{
BACKPROP=0,
RPROP = 1,
ANNEAL = 2
};
|
通过函数设置:
1
2
3
4
5
6
7
8
9
10
11
|
void setTrainMethod(int method, double param1 = 0, double param2 = 0);
int getTrainMethod();
|
OpenCV 提供的激活函数(目前,默认和唯一完全支持的激活函数是对称 Sigmoid):
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
| enum ActivationFunctions
{
IDENTITY = 0,
SIGMOID_SYM = 1,
GAUSSIAN = 2,
RELU = 3,
LEAKYRELU= 4
};
|
通过函数设置:
1
2
3
|
void setActivationFunction(int type, double param1 = 0, double param2 = 0);
|
部分参数如下:
LayerSizes:指定每层神经元的数量,包括输入和输出层。参数为向量,第一个元素指定了输入层中元素的数量。最后一个元素为输出层中元素的数量。默认值为空。
1
2
| void setLayerSizes(InputArray _layer_sizes);
cv::Mat getLayerSizes() const = 0;
|
BackpropWeightScale:权重梯度项的强度,
推荐值为0.1左右,默认值为0.1。
1
2
| double getBackpropWeightScale();
void setBackpropWeightScale(double val);
|
BackpropMomentumScale:动量项的强度,该参数提供了一些惯量来平滑权重的随机波动。默认值为0.1。
1
2
| double getBackpropMomentumScale();
void setBackpropMomentumScale(double val);
|
propDW0:RPROP 中的 Δ0,默认值为0.1。
1
2
| double getRpropDW0();
void setRpropDW0(double val);
|
RpropDWPlus:RPROP 中的增加因子 η+,默认值为1.2。
1
2
| double getRpropDWPlus();
void setRpropDWPlus(double val);
|
RpropDWMinus:RPROP 中的减少因子 η−,默认值为0.5。
1
2
| double getRpropDWMinus();
void setRpropDWMinus(double val);
|
RpropDWMin 和 RpropDWMax:RPROP 中的 Δmin(t) 和 Δmax(t)
1
2
3
4
5
6
7
|
double getRpropDWMin();
void setRpropDWMin(double val);
double getRpropDWMax();
void setRpropDWMax(double val);
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
double getAnnealInitialT();
void setAnnealInitialT(double val);
double getAnnealFinalT();
void setAnnealFinalT(double val);
double getAnnealCoolingRatio();
void setAnnealCoolingRatio(double val);
int getAnnealItePerStep();
void setAnnealItePerStep(int val);
void setAnnealEnergyRNG(const RNG& rng);
|
例子-糖尿病预测(MLP)
数据集在贝叶斯分类器学习记录中使用过,详见贝叶斯分类器。
数据集属性如下:
- Pregnancies: 怀孕次数
- Glucose:血浆葡萄糖浓度
- BloodPressure:舒张压
- SkinThickness:肱三头肌皮肤褶皱厚度
- Insulin:两小时胰岛素含量
- BMI:身体质量指数,即体重除以身高的平方
- DiabetesPedigreeFunction:糖尿病血统指数,即家族遗传指数
- Age:年龄
使用 MLP 进行预测结果与贝叶斯分类器比较如下:
1
2
3
4
5
6
7
8
9
10
11
| Train Data imported: 668
Test Data imported: 100
正态贝叶斯分类器:
计算花费时长:0ms
正确率:0.76
Train Data imported: 668
Test Data imported: 100
神经网络(BP)算法(基于OpenCV实现):
计算花费时长:230ms
正确率:0.82
|
代码地址:Gitee - ANN_MLP