关键词:C++、Linux
References:
Linux下操作。
零、前言
这个项目原作者暂未更新,单凭我自己的话,还没能力续写下去。我的想法是有时间再重新组织一下语言,细化一下每一章的描述。这个项目作为一个 Linux 网络编程的入门项目还是相当不错的,能够了解到 Socket、线程池以及一系列抽象编程思想。如果想继续深入学习网络编程,那路还有很长很长……
——Fingsinz,2024.06.06留
碰巧看到一位大牛在原仓库的基础上专注于功能的实现。
Reference:https://github.com/Wlgls/30daysCppWebServer
——Fingsinz,2024.07.11留
一、从socket开始
socket,被翻译为套接字,它是计算机之间进行通信的一种约定或一种方式。套接字是双方通过网络进行通信的通道。Socket 连接的一边是客户端,另一边是服务器端。一个正常的服务器端能服务多个客户端。
- 通过 socket 这种约定,一台计算机可以接收其他计算机的数据,也可以向其他计算机发送数据。
1.1 服务端干了什么
在服务器端,需要建立一个 socket 套接字,对外提供一个网络通信接口。
- 在 Linux 系统中这个套接字仅仅是一个文件描述符,也就是一个int类型的值。
- 对套接字的所有操作(包括创建)都是最底层的系统调用。
- 创建套接字:
1 | int sockfd = socket(AF_INET, SOCK_STREAM, 0); |
- 创建一个
sockaddr_in结构体并初始化(bzero函数):
1 | struct sockaddr_in serverAddr; |
- 设置地址族、IP 地址和端口号:
1 | serverAddr.sin_family = AF_INET; |
- 将 socket 地址与文件描述符绑定:
1 | bind(sockfd, (struct sockaddr *)&serverAddr, sizeof(serverAddr)); |
- 使用
listen函数监听套接字:
1 | listen(sockfd, SOMAXCONN); |
- 服务端想要接受一个客户端连接,需要使用
accept函数:
1 | struct sockaddr_in clientAddr; |
- 输出 socket 连接信息:
1 | printf("Client connected: %d!\tIP: %s\tPort: %d\n", clientSockfd, inet_ntoa(clientAddr.sin_addr), ntohs(clientAddr.sin_port)); |
至此,客户端已经可以通过 IP 地址和端口号连接到这个 socket 端口了。
1.2 客户端如何配合
在客户端,也需要建立一个 socket 套接字。
对于客户端,服务器存在的唯一标识是 IP 地址和端口号。此时需要将套接字绑定到一个 IP 地址和端口上。
- 创建套接字:
1 | int sockfd = socket(AF_INET, SOCK_STREAM, 0); |
- 创建一个
sockaddr_in结构体,并绑定 IP 族、IP 地址和端口号:
1 | struct sockaddr_in serverAddr; |
- 使用
connect函数进行连接:
1 | connect(sockfd, (sockaddr *)&serverAddr, sizeof(serverAddr)); |
注意,需要先 ./server 运行服务端进行等待,再 ./client 运行客户端进行连接请求。
1.3 该节涉及函数及源代码
- 相关头文件:
1 |
- 创建 socket:
1 | int socket (int __domain, int __type, int __protocol); |
- 初始化:
1 | void bzero (void *__s, size_t __n); |
- 绑定函数:
1 | int bind (int __fd, __CONST_SOCKADDR_ARG __addr, socklen_t __len); |
listen函数:
1 | int listen (int __fd, int __n); |
accept函数:
1 | int accept (int __fd, __SOCKADDR_ARG __addr, socklen_t *__restrict __addr_len); |
connect函数:
1 | int connect (int __fd, __CONST_SOCKADDR_ARG __addr, socklen_t __len); |
关于 Socket 的有些地址结构需要清楚:
1 | // 通用的套接字地址类型 |
-
struct sockaddr_storage对于IPv4和IPv6都足够大,可以在实际中使用它。 -
struct sockaddr_in和struct sockaddr_in6是IPv4和IPv6的具体结构。
struct sockaddr * 是 socket API 使用的类型,结构本身是无用的。程序员不应操作 sockaddr,sockaddr 是给操作系统用的。应使用 sockaddr_in 来表示地址,sockaddr_in 区分了地址和端口,将 struct sockaddr_storage 引用(指针)转换为 struct sockaddr_in 或 struct sockaddr_in6 以初始化/读取结构。
当在 Linux 上调用任何系统调用时,实际上是在调用 libc 中的一个瘦包装器,即一个稳定的 Linux 系统调用接口的包装器。在 Windows 上,套接字 API 遵循相同的 BSD API,但有许多不同的细节。接口来自 OS DLL 而不是系统调用。
二、完善代码,数据读写
上面的代码是基础版的,但要想真正运行使用,需要完善代码,并抓住错误。
- Effective C++ 中有提到:“别让异常逃离析构函数”(条款08)。
2.1 错误检查处理函数
对于 Linux 系统调用,常见的错误提示方式是使用返回值和设置错误码。
- 当一个系统调用返回
-1,说明有错误发生。
增加一个错误检查处理函数:
1 | void errorif(bool condition, const char *errmsg) |
- 第一个参数为判断是否发生错误条件,调用
iostream中的perror打印错误。 - 第二个参数为错误信息。
- 然后使用
exit函数让程序退出并返回一个预定义常量EXIT_FAILURE。
使用就很方便:
1 | int sockfd = socket(AF_INET, SOCK_STREAM, 0); |
对所有函数都进行处理错误:
1 | errorif(bind(sockfd, (struct sockaddr *)&serverAddr, sizeof(serverAddr)) == -1, "socket bind error"); |
- 错误的处理是必须的,但处理函数不一定这样写。
2.2 数据读写
当建立 socket 连接后,就可以使用 unistd.h 中的 read 和 write 函数进行数据读写。(仅限于 TCP 连接。UDP 连接使用 sendto 和 recvfrom 函数。)
接下来做一个通信情况:客户端向服务端发送一定数据,然后服务端接收后转发回客户端,客户端将接收的转发数据再进行标准输出。
客户端:
1 | while (true) // 持续通信 |
服务端:
1 | while (true) |
需要注意的是:
- 服务端和客户端都可以从对方中读写数据。
- 使用完一个
fd(文件描述符) 后,记得使用close函数进行关闭。
2.3 该节涉及函数及源代码
- 相关头文件:
1 |
write函数:
1 | ssize_t write (int __fd, const void *__buf, size_t __n); |
read函数:
1 | ssize_t read (int __fd, void *__buf, size_t __nbytes); |
close函数:
1 | int close (int __fd); |
三、高并发使用epoll
之前只写了一个简单的服务器,只能同时处理一个客户端连接。事实上,所有的服务都是高并发的,可以同时为成千上万个客户端提供服务——IO复用。
- IO 复用和多线程相似,但不是一个概念。
- IO 复用针对 IO 接口;
- 多线程针对 CPU。
IO 复用的基本思想是事件驱动,服务器同时保持多个客户端 IO 连接。
- 当 IO 上有可读或可写事件发生,表示这个 IO 对应的客户端在请求服务器的服务,服务器应当响应。
- Linux 中, IO 复用使用 select、poll 和 epoll 来实现。
- epoll 相比 select、poll,表现性能更好,更加高效。
3.1 从select、poll到epoll
从实现原理上来说,select 和 poll 采用的都是轮询的方式,即每次调用都要扫描整个注册文件描述符集合,并将其中就绪的文件描述符返回给用户程序,因此它们检测就绪事件的算法的时间复杂度是 。epoll_wait 则不同,它采用的是回调的方式。内核检测到就绪的文件描述符时,将触发回调函数,回调函数就将该文件描述符上对应的事件插人内核就绪事件队列。内核最后在适当的时机将该就绪事件队列中的内容拷贝到用户空间。因此 epoll_wait 无须轮询整个文件描述符集合来检测哪些事件已经就绪,其算法时间复杂度是 。详见《Linux高性能服务器编程-游双,第9章》
- 当活动连接比较多的时候,epoll_wait 的效率未必比 select 和 poll 高,因为此时回调函数被触发得过于频繁。所以 epoll_wait 适用于连接数量多,但活动连接较少的情况。
epoll 是 Linux 特有的 IO 复用函数。
- 使用一组函数完成任务。
- 把用户关心的文件描述符上的事件放到内核的一个事件表中。
- 而不像 select 和 poll 那样每次调用都重复传入文件描述符或事件集。
- 需要额外的文件描述符来标识内核中的事件表。
创建文件描述符:
1 |
|
操作 epoll 的内核事件表:
1 | int epoll_ctl(int epfd, int op, int fd, struct epoll_event *event); |
而关于 epoll_event 结构体的定义:
1 | struct epoll_event |
epoll 系列系统调用的主要接口是 epoll_wait 函数,它在一段超时时间内等待一组文件描述符上的事件:
1 | int epoll_wait(int epfd, struct epoll_event *events, int maxevents, int timeout); |
epoll 对文件描述符的操作有两种:
- LT(Level Trigger,电平触发)模式
- 默认的工作模式,相当于效率较高的 poll。
- 对于采用 LT 工作模式的文件描述符,当 epoll_wait 检测到其上有事件发生并将此事件通知应用程序后,应用程序可以不立即处理该事件。这样,当应用程序下一次调用 epoll,_wait 时,epoll_wait 还会再次向应用程序通告此事件,直到该事件被处理。
- ET(Edge Trigger,边沿触发)模式
- 对于采用ET工作模式的文件描述符,当 epoll_wait 检测到其上有事件发生并将此事件通知应用程序后,应用程序必须立即处理该事件,因为后续的epoll_wait 调用将不再向应用程序通知这一事件。可见,ET 模式在很大程度上降低了同一个 epoll 事件被重复触发的次数,因此效率要比 LT 模式高。
- ET 模式必须搭配非阻塞式 socket 使用。
epoll 的事件有:
EPOLLIN:表示对应的文件描述符可读(包括对端 socket 正常关闭);EPOLLOUT:表示对应的文件描述符可写;EPOLLPRI:表示对应的文件描述符有紧急的数据可读(表示有带外数据到来);EPOLLERR:表示对应的文件描述符发生错误;EPOLLHUP:表示对应的文件描述符被挂断;EPOLLET:将 epoll 设为边缘触发模式。EPOLLONESHOT:只监听一次事件,当监听完事件后,如果还需要继续监听这个 socket 的情况下,需要再次把这个 socket 加到 epoll 队列里。
3.2 将服务器改写成epoll版本
在创建了服务器 socket fd 后,将这个 fd 添加到 epoll。
- epoll 监听事件的描述符会放在一棵红黑树上,将要监听的 IO 口放入 epoll 红黑树中,就可以监听该 IO 上的事件。
- 只要这个 fd 上发生可读事件,表示有一个新的客户端连接。
- 然后 accept 这个客户端并将客户端的 socket fd 添加到 epoll,epoll 会监听客户端 socket fd 是否有事件发生,如果发生则处理事件。
所以服务器大概的步骤如下:
- 创建 epoll,同时定义事件数组。
1 | // 创建 epoll |
- 将要监听的 IO 口放入 epoll 中。
1 | ev.data.fd = sockfd; // 该 IO 口为服务器 socket fd |
-
不断监听 epoll 上的事件并处理。
-
如果监听发生的事件是服务器 socket fd 上的事件,表示有一个新的客户端连接。
1 | if (events[i].data.fd == sockfd) |
- 如果监听发生的事件是客户端,并且是可读事件,表示有客户端发送消息:
1 | else if (events[i].events & EPOLLIN) |
四、封装成类,程序模块化
4.1 将socket和InetAddress封装成类
当新建服务器 socket 时,需要完成绑定 IP 地址、监听、接受客户端连接等任务,这些任务都封装成 Socket 类来完成。希望简化成以下操作:
1 | // 新建服务器 socket |
4.2 将epoll封装成类
对于 epoll,希望简化操作,封装成类后:
1 | // 实例化 epoll |
4.3 目录结构及源代码
目录结构如下:
1 | client.cpp |
五、向着Reactor模式转变
5.1 Reactor和Proactor
Reactor 翻译过来的意思是「反应堆」,这里的反应指的是「对事件反应」。
- 当来了一个事件,Reactor 就有相对应的反应/响应。
事实上,Reactor 模式也叫 Dispatcher 模式,我觉得这个名字更贴合该模式的含义,即 I/O 多路复用监听事件。
- 收到事件后,根据事件类型分配(Dispatch)给某个进程 / 线程。
Reactor 模式主要由 Reactor 和处理资源池这两个核心部分组成。
- Reactor 负责监听和分发事件,事件类型包含连接事件、读写事件;
- 处理资源池负责处理事件,如 read -> 业务逻辑 -> send;
Reactor 模式是灵活多变的,可以应对不同的业务场景,灵活在于:
- Reactor 的数量可以只有一个,也可以有多个;
- 处理资源池可以是单个进程 / 线程,也可以是多个进程 / 线程;
有 3 个方案都是比较经典的,且都有应用在实际的项目中:
- 单 Reactor 单进程 / 线程;
- 单 Reactor 多线程 / 进程;
- 多 Reactor 多进程 / 线程;
方案具体使用进程还是线程,要看使用的编程语言以及平台有关:
- Java 语言一般使用线程,比如 Netty;
- C 语言使用进程和线程都可以,例如 Nginx 使用的是进程,Memcache 使用的是线程。
Reactor 是非阻塞同步网络模式,感知的是就绪可读写事件。在每次感知到有事件发生(比如可读就绪事件)后,就需要应用进程主动调用 read 方法来完成数据的读取,也就是要应用进程主动将 socket 接收缓存中的数据读到应用进程内存中,这个过程是同步的,读取完数据后应用进程才能处理数据。
Proactor 是异步网络模式, 感知的是已完成的读写事件。在发起异步读写请求时,需要传入数据缓冲区的地址(用来存放结果数据)等信息,这样系统内核才可以自动帮我们把数据的读写工作完成,这里的读写工作全程由操作系统来做,并不需要像 Reactor 那样还需要应用进程主动发起 read/write 来读写数据,操作系统完成读写工作后,就会通知应用进程直接处理数据。
因此,Reactor 可以理解为「来了事件操作系统通知应用进程,让应用进程来处理」,而 Proactor 可以理解为「来了事件操作系统来处理,处理完再通知应用进程」。这里的「事件」就是有新连接、有数据可读、有数据可写的这些 I/O 事件这里的「处理」包含从驱动读取到内核以及从内核读取到用户空间。
作者:小林coding
链接:https://www.zhihu.com/question/26943938/answer/1856426252
来源:知乎著作权归作者所有。
详细请参考游双《Linux高性能服务器编程》第八章第四节、陈硕《Linux多线程服务器编程》第六章第六节。
接下来要将服务器向着 Reactor 模式转变:
- 首先将整个服务器抽象成一个 Server 类,这个类中有一个 main-Reactor,里面的核心是一个 EventLoop,这是一个事件循环;
- 添加需要监听的事务到这个事件循环内,每次有事件发生时就会通知,在程序中返回给 Channel(自封装的类),然后根据不同的描述符、事件类型以回调函数的方式进行处理。
5.2 加入Channel类
面对服务器许多服务时,不同的连接类型也将决定不同的处理逻辑,仅仅通过一个文件描述符来区分显然会很麻烦。希望得到文件描述符的更多消息。
- epoll 的
epoll_event结构体中,data字段可以放一个void *类型的指针,用来保存更多信息。
1 | typedef union epoll_data |
- epoll 中的
data是一个联合类型:- 可以存储一个指针,指向任何一个地址块的内容;
- 可以是一个类的对象,就此将一个文件描述符封装成一个
Channel类,一个Channel类始终负责一个文件描述符。对不同的服务、不同的事件类型,都可以在类中进行处理。
设计 Channel 类,核心成员如下:
1 | class Channel |
loop:指向与之关联的事件循环的指针。fd:Channel 负责的文件描述符。events:表示希望监听这个文件描述符的哪些事件。revents:表示在epoll返回该Channel时文件描述符正在发生的事件。isEpoll:表示当前Channel是否已经添加到epoll红黑树中,区分使用EPOLL_CTL_ADD还是EPOLL_CTL_MOD。callback:发生事件时执行的回调函数。
添加 Channel 类可以更加方便简单、多样化地处理 epoll 中发生的事件。同时脱离了底层,将 epoll、文件描述符和事件进行了抽象,形成了事件分发的模型,这也是 Reactor 模式的核心。
5.3 加入EventLoop类
EventLoop 类的定义如下:
1 | class EventLoop { |
ep:指向Epoll类实例的指针;quit:指示程序是否应该退出;loop():事件循环函数,调用开始事件驱动,即原来调用epoll_wait函数的死循环;updateChannel():更新 Channel。
将需要监听的事务加入到事件循环中,每次有事件发生就会通知,返回到 Channel,然后根据不同的描述符、事件类型以回调函数方式进行处理:
1 | void EventLoop::loop() |
5.4 加入Server类
服务器类 Server 的核心成员如下:
1 | class Server |
loop:事件循环对象。handleReadEvent():处理读事件。newConnection():处理新连接。
之后启动服务器的操作抽象为:
1 | EventLoop *loop = new EventLoop(); |
这个版本服务器内只有一个 EventLoop,当其中有可读事件发生时,可以拿到该描述符对应的 Channel。
在新建 Channel 时,根据 Channel 描述符的不同分别绑定了两个回调函数:
newConnection()函数被绑定到服务器socket上;- 如果服务器 socket 有可读事件,Channel 里的
handleEvent()函数实际上会调用 Server 类的newConnection()新建连接。
- 如果服务器 socket 有可读事件,Channel 里的
handlrReadEvent()被绑定到新接受的客户端socket上。- 如果客户端 socket 有可读事件,Channel 里的
handleEvent()函数实际上会调用 Server 类的handleReadEvent()响应客户端请求。
- 如果客户端 socket 有可读事件,Channel 里的
至此,根据抽象出的 EventLoop 和 Channel,构成了事件驱动模型。这两个类和服务器核心 Server 已经没有任何关系,经过完善后可以被任何程序复用,达到了事件驱动的设计思想,现在的服务器也可以看成一个最简易的 Reactor 模式服务器。
需要注意的是,目前该服务器的内存管理一塌糊涂。
六、把服务器的接受抽象化
6.1 抽象化接受
服务器中,对于每一个事件,首先都是调用 accept() 函数去接受一个 TCP 连接,然后把 Socket 文件描述符添加到 epoll。当这个 IO 口有事件发生时,对该连接提供相应的服务。
分离接受连接这个功能,添加 Acceptor 类。
6.2 Acceptor 类
Acceptor 类应该有以下特点:
- 类中有一个 Socket fd,就是服务器监听的 Socket fd,每一个
Acceptor 对象都对应一个 Socket fd。 - 类存在于事件驱动
EventLoop类中。 - 类也通过一个
Channel负责分发到 epoll,该Channel的事件处理函数handleEvent()会调用Acceptor类中的连接函数进行新建一个 TCP 连接。
将新建连接的逻辑就在 Acceptor 类中。但逻辑上新 Socket 建立后就和之前的监听的服务器 Socket 没有任何关系了。
新的 TCP 连接应该由 Server 类来创建并管理生命周期,而不是 Acceptor。并且将一部分代码放在 Server 类里也并没有打破服务器的通用性,因为对于所有的服务,都要使用 Acceptor 来建立连接。
Acceptor类的新建连接功能是在Server类中实现的。
可以使用 std::function、std::bind、右值引用、std::move 等实现函数回调。
定义该类:
1 | class Acceptor |
抽象后,Server类的变化如下:
1 | // 之前 |
七、把TCP连接抽象化
7.1 抽象化连接
对于 TCP 协议,在三次握手新建连接后,该连接会一直存在直至四次挥手断开连接。
那么把这个连接也抽象化,抽象成 Connection 类。
7.2 Connection 类
Connection 类应该有以下特点:
- 类存在于事件驱动类中;
- 类的 Socket fd 就是客户端的 Socket fd,每一个
Connection 对象都对应一个 Socket fd。 - 类也通过一个
Channel负责分发到 epoll,该Channel的事件处理函数handleEvent()会调用Connection类中的事件处理函数进行响应客户端请求。
Connection 类与 Acceptor 类十分相似,它们都由 Server 管理,由一个 Channel 分发到 epoll,通过回调函数处理响应事件。
一个高并发服务器一般只有一个 Acceptor(可以有多个),但会同时有成千上万个 TCP 连接,也就是 Connection 的实例。
对 Connection 类的定义如下:
1 | class Connection |
7.3 改写 Server 类
Server 类的核心变成:
1 | class Server |
- 通过
Map映射将众多连接保存起来,键为该连接客户端的socket fd,值为指向该连接的指针。 - 该连接客户端的
socket fd通过一个Channel类分发到epoll,该Channel的事件处理回调函数handleEvent()绑定为Connection的处理函数,这样每当该连接的socket fd上发生事件,就会通过Channel调用具体连接类的处理函数。
此处将新建连接的功能放回到 Acceptor 类中管理:
1 | void Acceptor::acceptConnection() |
Server 类变得只负责管理 Acceptor 和 Connection 类,其成员函数也集中在管理 Acceptor 和 Connection 类中。改写后的 Server 类代码如下:
1 | void Server::newConnection(Socket *_socket) |
- 当有新的 TCP 连接时,实例化一个
Connection对象,设置其删除时的回调函数,并放置在connections中管理。- 目前该服务器的唯一功能——接受客户端的信息并发回,封装成
Connection类的echo函数,在Connection构造时绑定给Channel类的事件回调函数,由Channel实例遇到事件时触发。
- 目前该服务器的唯一功能——接受客户端的信息并发回,封装成
- 当有 TCP 连接断开时,从
connections中删除该连接,并释放对象。- 由于
Connection的生命周期由Server进行管理,所以也应该由Server来删除连接
- 由于
至此,服务器到了一个比较重要的阶段,服务器最核心的几个模块都已经抽象出来,一个完整的单线程服务器设计基本完成。
八、闲来无事,整个缓冲区
8.1 引入缓冲区
此节引入一个最简单、最基本的缓冲区,完善改进之前的服务器。
没有使用缓冲区时,服务器回送信息的代码如下:
1 | void Connection::echo(int sockfd) |
- 这是非阻塞式 socket IO 的读取,缓冲区大小为 1024,表示每次 TCP 缓冲区读取 1024 大小的数据到缓冲区,然后发送到客户端。
- 只能以 1024 地读,当数据没有 1024,用空值补满。
所以,封装一个缓冲区,为每一个 Connection 类分配一个读缓冲区和写缓冲区:
- 从客户端读来的数据存放在都缓冲区。
8.2 Buffer类
Buffer 类的代码如下:
1 |
|
使用如下:
1 | /* src/Connection.cpp */ |
虽然仍有 char buf[1024] 这样的低级缓冲区,用于系统调用 read() 的读取,但这个缓冲区大小无所谓,设置为1到设备TCP缓冲区的大小都可以。
- 太大导致资源浪费,单词读取速度低;
- 太小导致读取次数增多。
以上代码会把 socket IO 上的可读数据全部读取到缓冲区,缓冲区大小就等于客户端发送的数据大小。全部读取完成之后,可以构造一个写缓冲区、填好数据发送给客户端。
- 由于是echo服务器,所以这里使用了相同的缓冲区。
8.3 其他方面的改进
-
优化 InetAddress 类,将成员私有化,提供访问方法。(——
src/InetAddress.h和src/InetAddress.cpp) -
Socket 类添加
connect方法,方便client.cpp调用。(——src/Socket.h和src/Socket.cpp) -
结合现有的模块,改进 client 文件。(——
client.cpp) -
整体改进了了输出信息提示。


九、线程池啊线程池
9.1 为什么加入线程池
当前的代码是单线程模式,所有 fd 上的事件都由一个线程(主线程,EventLoop线程)处理。
- 假设响应一个事件需要 1s,那么如果有 1000 个事件,那么主线程就要等待很久。
- 这不现实。
引入多线程,当发现 socket fd 有事件时,应该分发一个工作线程。
- 由这个工作线程处理 fd 上的事件。
再者,每一个 Reactor 只应该负责事件分发而不负责事件处理。
9.2 如何设计线程池
最简单的想法就是,每次遇到一个新的任务,就开一个新线程去执行。
- 这种方式虽然简单,但是太粗暴了。
- 我们的机器是有上限的,不可能无限开新线程。
那么,可以固定一个线程的数量。启动固定数量的工作线程,然后将任务添加到任务队列,工作线程不断取出任务队列的任务执行。
设计线程池还需要注意:
- 多线程环境下任务队列的读写应该考虑互斥锁。
- 当任务队列为空时,CPU 不应该一直轮询耗费 CPU 资源。
此处解决方法如下:
std::mutex对任务队列进行加锁解锁。std::condition_variable使用条件变量。
9.3 线程池用到的语法知识
关于互斥锁:mutex头文件 - cppreference
mutex类是能用于保护共享数据免受从多个线程同时访问的同步原语。lock():成员函数,锁定互斥体,若互斥体不可用则阻塞。位于头文件<mutex>。- 通常不直接调用
lock()。 - 用
std::unique_lock与std::lock_guard管理排他性锁定。 unique_lock类是一种通用互斥包装器,允许延迟锁定、有时限的锁定尝试、递归锁定、所有权转移和与条件变量一同使用。- 构造函数:
explicit unique_lock( mutex_type& m );,通过调用m.lock()锁定关联互斥体。 - 析构函数:若拥有关联互斥体且获得了其所有权,则解锁互斥体。
- 通常不直接调用
try_lock():成员函数,尝试锁定互斥体,若互斥体不可用则返回false。位于头文件<mutex>。unlock():成员函数,解锁互斥体。位于头文件<mutex>。
关于线程等待条件:condition_variable头文件 - cppreference
std::condition_variable(线程等待条件) 是与std::mutex一起使用的同步原语。- 它能用于阻塞一个线程,或同时阻塞多个线程,直至另一线程修改共享变量(条件)并通知
std::condition_variable。 - 有意修改变量的线程必须:
- 获得
std::mutex(常通过std::lock_guard) - 在保有锁时进行修改
- 在
std::condition_variable上执行notify_one或notify_all(可以释放锁后再通知)
- 获得
- 任何有意在
std::condition_variable上等待的线程必须:- 在用于保护共享变量的互斥体上获得
std::unique_lock<std::mutex>。 - 执行下列之一:
- 检查条件,是否为已更新且已提醒的情况。
- 调用
std::condition_variable的wait、wait_for或wait_until(原子地释放互斥体并暂停线程的执行,直到条件变量被通知,时限过期,或发生虚假唤醒,然后在返回前自动获得互斥体)。 - 检查条件,并在未满足的情况下继续等待。
- 在用于保护共享变量的互斥体上获得
wait():成员函数,阻塞当前进程,直至条件变量被唤醒。位于头文件<condition_variable>。- 类似还有
wait_for、wait_until。不多说,自行查阅。
- 类似还有
notify_one():成员函数,通知一个等待的线程。位于头文件<condition_variable>。notify_all():成员函数,通知所有等待的线程。位于头文件<condition_variable>。
9.4 线程池类
线程池类代码如下:
1 | class ThreadPool |
线程池的构造函数设计为:
1 | ThreadPool::ThreadPool(int size) : stop(false) |
- 初始线程池大小为
size,创建线程并让每个线程等待将任务添加到任务队列中。 - 使用
std::unique_lock锁定任务互斥锁以防止并发访问,并将其置于局部作用域,当离开作用域时,它将自动解锁互斥锁。 - 当添加任务时,线程从队列中获取任务并执行它。线程将继续执行任务,直到线程池停止。
析构函数设计为:
1 | ThreadPool::~ThreadPool() |
- 在线程池析构时,需要注意将已经添加的所有任务执行完,最好不采用外部的暴力kill、而是让每个线程从内部自动退出,具体实现参考源代码。
- 在上锁的情况下,把线程池的停止状态设置为
true,然后通知所有等待的线程线程池正在停止。 - 然后,等待所有线程完成其执行。
加入线程池后,当 Channel 类有事件需要处理时,将这个事件处理添加到线程池,主线程 EventLoop 就可以继续进行事件循环,而不在乎某个 socket fd 上的事件处理。
十、有了线程池之后的考虑
10.1 完善线程池
上一节添加的线程池是最简单的线程池,还存在许多问题,比如:
- 任务队列的添加、取出都会有不必要的拷贝操作;
- 线程池只接受
std::function<void>类型的参数,所有函数参数都要事先使用std::bind(),并且无法得到返回值。
解决方法一一对应:
- 使用右值移动去避免拷贝操作。
- 改写
add()函数,希望使用前不需要手动绑定参数,直接传递并且可以得到任务的返回值。
10.2 完善线程池用到的语法知识
关于模板编程:模板 - MSLearn、理解C++模板 - 知乎
- 简单来说,模板编程就是提供了一套模具,对于不同的数据类型都可以适用于这套模具。
- 函数模板的结构一般如下:
1 | template <typename T> 返回类型 函数名(参数列表){ /*函数的主体*/ } |
- 类模板结构一般如下:
1 | template <class T> class 类名 {} |
- 变长参数模板:参数个数和类型都可能发生变化的模板。
- 使用模板形参包实现。
- 模板形参包是可以接受 0 个或者 n 个模板实参的模板形参,至少有一个模板形参包的模板就可以称作变参数模板。
- 模板形参包有:非类型模板形参包、类型模板形参包、模板模板形参包三种。
- 此节使用类型模板形参包:表示该可变形参包可以接受无限个不同的实参类型。
1 | typename... Args 或 class ... Args |
关于右值和移动 std::move:C++引用和右值引用 - CSDN、【C++】C++11——左右值|右值引用|移动语义|完美转发、一文读懂C++右值引用和std::move - 知乎
- C++11 后增加了移动语义,出现了移动构造、移动赋值等。
- 简单来说,移动语义的出现,可以把旧对象所拥有的资源交给新对象,而旧对象什么都没有了。
- 右值引用的出现也是为了移动语义。
关于完美转发 std::forward:
- 和
std::move类似,与std::move相比,它更强大,move只能转出来右值,forward都可以。 std::forward<T>(u)有两个参数:T与u。- 当
T为左值引用类型时,u将被转换为T类型的左值; - 否则
u将被转换为T类型右值。
- 当
关于 std::future:future - cppreference
- 类模板
std::packaged_task可以包装任何可调用 (Callable) 目标(函数、lambda 表达式、bind 表达式或其他函数对象),使得能异步调用它。其返回值或所抛异常被存储于能通过 std::future 对象访问的共享状态中。- 成员函数
get_future(),返回与*this共享同一共享状态的future,每个packaged_task对象只能调用一次。
- 成员函数
- 类模板
std::future:future对象提供访问异步操作结果的机制,从异步任务中返回结果。 - 类模板
std::future提供访问异步操作结果的机制:- (通过
std::async、std::packaged_task或std::promise创建的)异步操作能提供一个std::future对象给该异步操作的创建者。 - 然后,异步操作的创建者可以使用多个方法查询、等待或从
std::future提取值。若异步操作尚未提供值,则这些方法可能阻塞。 - 当异步操作准备好发送结果给创建者时,它可以修改与创建者的
std::future相链接的共享状态(例如std::promise::set_value)。
- (通过
10.3 再修修补补
除了上面线程池的部分有修改,以下部分也有修改:
Channel 部分:
- 新增标记位和是否使用线程池的函数;
- 对于处理事件区分了读事件和写事件分别的回调函数;
- 新增可选择性 epoll ET 模式或 epoll LT 模式;
Acceptor 部分:因为接受连接处理时间短、报文数据小,也不会有同时到达的新连接,所以
- Acceptor 的 socket fd (服务器监听 socket)使用阻塞式:
- Acceptor 从 epoll ET 模式改为 epoll LT 模式,建立好连接后处理事件 fd 读写用 ET 模式。
- Acceptor 的连接建立不适用线程池,建立好连接后处理事件使用线程池。
Connection 部分:
- 新增
send()函数,独立发送数据。 - 修改
deleteConnectionCallback()函数,参数类型改为int。
Epoll 部分:
- 新增
deleteChannel()函数,用于删除 Channel。
Server 部分:
- 新增
deleteConnection()函数。
更多细节上的变化(可能有部分错误处理、变量变化)可比较前一天的文件。
服务器中还可能有潜在的bug。
最后,添加测试连接的程序 test.cpp,使用命令 make t 编译,使用如下:
1 | ./test -t 1000 -m 10 -w 100 |
-t表示线程数量,此处为 1000 个线程进行服务器连接;-m表示每个线程的回显次数,此处为每个线程回显 10 次;-w表示每个线程的等待时间,可以测试最大连接数,可以不设置。
十一、改写成主从Reactor多线程模式
11.1 什么是主从Reactor多线程模式
现在实现的服务器多线程 Reactor 模式,是给每一个 Channel 的任务分配一个线程执行。但目前的线程池对象置于 EventLoop 中,而不是由服务器类 Server 类管理。
主从 Reactor 多线程模式是大多数高性能服务器采用的模式。
陈硕《Linux多线程服务器编程》书中的 one loop per thread 模式。
该模式的特点有:
- 服务器一般只有一个 main Reactor,有多个 sub Reactor。
- 服务器管理一个线程池,每一个 sub Reactor 由一个线程来负责 Connection 上的事件循环,事件执行也在这个线程中完成。
- main Reactor 只负责 Acceptor 建立新连接,然后将这个连接分配给一个 sub Reactor。
11.2 代码上的变化
根据主从 Reactor 多线程模式的特点,将服务器类重写如下:
1 | class Server |
在有一个新连接到来时,采用随机调度策略分配给一个 subReactor:
1 | int random = _socket->getFd() % subReactors.size(); |
- 这种调度算法适用于每个socket上的任务处理时间基本相同,可以让每个线程均匀负载。但事实上,不同的业务传输的数据极有可能不一样,也可能受到网络条件等因素的影响,极有可能会造成一些 subReactor 线程十分繁忙,而另一些 subReactor 线程空空如也。此时需要使用更高级的调度算法,如根据繁忙度分配,或支持动态转移连接到另一个空闲 subReactor 等。
调度问题是个很有趣的问题,会直接影响服务器的效率和性能。
代码上,还将原来在 EventLoop 的线程池去掉,Channel 也不再区分是否使用线程池。
现在,服务器以事件驱动为核心,服务器线程只负责 mainReactor 的新建连接任务,同时维护一个线程池,每一个线程是一个事件循环,新连接建立后分发给一个 subReactor 开始事件监听,有事件发生则在当前线程处理。
十二、项目工程化
目前服务器的结构是主从 Reactor 多线程模式,是比较主流的模式。所以大体上的方向已经确定,接下来对细节进行优化,把项目工程化。
12.1 认识Cmake
首先,CMake是一个跨平台的编译工具,可以用简单的语句进行编译。
一个项目使用 CMake 维护一个 CMakeLists.txt 配置文件来描述一个项目的编译过程。利用这个文件,就可以搭建起来这个项目。
目前将所有文件都放在一个文件夹,并且没有分类。随着项目越来越复杂、模块越来越多,开发者需要考虑这座屎山的可读性,如将模块拆分到不同文件夹,将头文件统一放在一起等。
对于这样复杂的项目,如果手写复杂的Makefile来编译链接,那么将会相当负责繁琐。我们应当使用 CMake 来管理我们的项目,CMake 的使用非常简单、功能强大,会帮我们自动生成 Makefile 文件,使项目的编译链接更加容易,程序员可以将更多的精力放在写代码上。
这是 CmakeLists.txt 基本结构:
1 | # xxx:本 CMakeLists.txt 的 project 名称 |
12.2 工程化的实际操作
首先规范化目录的意义:
src目录(即source),用于存放核心的代码;include目录,用于存放源代码中的头文件;
test目录,用于存放测试的代码;
1 | projiect/ |
在这一章,我们使用的是一个 CMake 工程,所以 Visual Studio 创建的是 CMake 项目。接下来就是 CMake 的配置工作。(有关 CMake 的安装使用可参考附 2)
构建上述文件目录,将对应的文件分类进去。

接着,开始编写项目的根 CMakeLists.txt 文件(即根目录下的 CMakeLists.txt ):
1 | cmake_minimum_required(VERSION 3.10) # CMake运行的最小版本 |
- 第一次接触 CMake 命令可以参考注释理解。
接着,尝试把我们关于服务器的设计打包成一个库,即编写 src/CMakeLists.txt:
1 | # 设置包含目录 |
然后,把测试文件的 CMakeLists.txt(即 test/CMakeLists.txt)也编写一下,用于管理测试文件的编译:
1 | # 设置包含目录 |
当然,这章在代码上也有些许修改,比如函数参数做了 const &,类也禁止了拷贝和移动操作。
接着只需要把项目部署到远程 Linux 服务器,使用以下命令编译即可:
make server:编译服务端代码make SingleClient:编译单个客户端连接代码make MultipleClients:编译多个客户端连接代码make clean:清理生成
运行只需要:
./bin/server:启动服务端./bin/SingleClient:启动单个客户端连接./bin/MultipleClients -t 线程数 -m 回显消息数 -w 延时发送信息:启动多个客户端连接
原作者还进行了代码静态分析和代码格式化,详见地址:Github
十三、业务逻辑自定义化
13.1 业务逻辑思想
首先回顾之前的思想,我们目前服务器只有一个功能,就是进行回声(Echo):把客户端发来的消息再发送回去。而这个功能,或者说业务逻辑,就固定在 Connection 类。
而通过第十二章的设计,我们把网络方面的代码整合为一个链接库。很明显,作为一个库,并不能就这样把业务逻辑固定了,应该支持业务逻辑自定义。
业务逻辑由用户自定义,然后使用网络库进行服务器与客户端间的交互。
怎样事件触发、读取数据、异常处理等流程应该是网络库提供的基本功能,用户只应当关注怎样处理业务即可,所以业务逻辑的进入点应该是服务器读取完客户端的所有数据之后。这时,客户端传来的请求在
Connection类的读缓冲区里,只需要根据请求来分发、处理业务即可。
总体上,服务器端提出这样的设计:
- 具有一个
Server类和一个事件循环类。 - 通过回调函数的方式编写业务逻辑,传给
Server类的实例。- 只需关心服务器的处理方法,比如一个 Echo 服务器只需要把对方发来的信息发回去。通过设置
onMessage回调函数来自定义自己的业务逻辑,在服务器完全接收到客户端的数据之后,该函数触发。 - 可以设置连接时的业务逻辑和整个服务端的业务逻辑。
- 只需关心服务器的处理方法,比如一个 Echo 服务器只需要把对方发来的信息发回去。通过设置
1 | Server *server = new Server(loop); |
另外,希望客户端的代码也可以通过我们的网络库进行实现:将 Connection 类进行完善,使得其满足服务端(Server → Client)和客户端(Client → Server)的使用:
- 服务端和客户端的传输数据方向是相反的:对于服务端,它从客户端中读取数据,或者写入数据到客户端;对于客户端,它从服务端中读取数据,或者写入数据到服务端。
- 在发回数据时,应该考虑对方是否已经关闭了链接。所以还需要设计
Connection的状态。
总体上,客户端要使用 Connection 类,提出这样的设计:
- 提供
write()和read()函数。write()函数表示将写缓冲区里的内容发送到该Connection的 socket,发送后会清空写缓冲区;read()函数表示清空读缓冲区,然后将 TCP 缓冲区内的数据读取到读缓冲区。
- 考虑
Connection的状态State。
13.2 操刀动代码
根据上面的分析,Server 进行改动如下:
- 将
Server类进行改写:
1 | // Server.h |
但是我们不能急,修改 Server 必须还得对 Connection 类的完善。因为服务器的一些操作是通过连接类完成,改动如下:
- 添加连接状态(此处其实只关注是否连接建立即可):
1 | enum State |
- 提供读写函数(详细见章末 Gitee 或 Github 链接):
1 | void Connection::read() |
读操作和写操作区分是否阻塞:对于客户端,使用阻塞读写;对于服务端,使用非阻塞读写。在判断 Socket 是否阻塞时,需要添加个函数(之前没有)。
-
将原来成员属性
int fd变成Socket *mSocket。 -
添加上对应的回调函数及其
Set函数:
1 | std::function<void(Socket *)> mDeleteConnectionCallback; // 删除连接的回调函数 |
- 编写业务函数。在构建服务器时指定对客户端消息的响应,然后通过对
Server类的设置,传递到Connection类,最后传递到Channel类的handleEvent()进行调用。
1 | /** |
现在也差不多了,但是可以完善(重构)一下 Channel 类,让其意义更明确,更规范一些:
- 规范私有成员变量:
1 | private: |
- 编写相关成员函数(函数名修改后记得在对应调用处修改):
1 | // 处理事件 |
- 修改
Channel类的析构函数,其析构为loop调用deleteChannel()(需要添加函数)(实际上还是相关联的Epoll封装类去deleteChannel()):
1 | Channel::~Channel() |
在修改了 Channel 类后,其相关联的 Epoll 封装类也需要修改:
- 修改
Epoll::deleteChannel(Channel *channel),需要把当前的Channel对象从 epoll 中删除,然后设置有效性为false:
1 | void Epoll::deleteChannel(Channel *channel) |
- 完善
Epoll::updateChannel(Channel *channel):
1 | void Epoll::updateChannel(Channel *channel) |
- 完善
Epoll::poll(int timeout):
1 | vector<Channel *> Epoll::poll(int timeout) |
最后检查各个文件无报错后,根据需要修改 CMakeLists.txt 文件。
之后,如果想创建不一样功能的服务器,可以通用我们这样的一个网络库。
十四、再次重构,告一段落
14.1 重构思想
-
使用智能指针进行内存管理。在之前的开发中,使用的都是原始的指针,但是原始的指针对内存管理而言是困难的,极易产生内存泄漏、悬垂引用、野指针等问题。从 C++11 标准后,可以使用智能指针来管理内存,让程序员无需过多考虑内存资源的使用。
std::unique_ptrstd::shared_ptrstd::weak_ptr
-
避免资源的复制操作,尽量使用移动语义来进行所有权的转移,这对提升程序的性能有十分显著的帮助。
-
对错误、异常的处理。在项目上线后,我们不能因为某些错误就直接让程序崩溃或者终止。而且,绝大部分错误都是可恢复的:
- 如创建 socket 失败可能是文件描述符超过操作系统限制,稍后再次尝试即可。
- 监听 socket 失败可能是端口被占用,切换端口或提示并等待用户处理即可。
- 打开文件失败可能是文件不存在或没有权限,此时只需创建文件或赋予权限即可。
- 所以在底层的编码上,对于部分错误需要进行可恢复处理,避免一个模块或资源发生的小错误影响整个服务器的运行。
14.2 加入.clang-fromat
Clang 本身是一个 C++ 的编译器。而 Clang-Format 是其中的一个格式化工具,可用于格式化(排版)多种不同语言的代码。在 Linux 中安装一下 clang-format:
1 | sudo apt install -y clang-format |
如果使用 VSCode 进行编程的话,需要安装插件 Clang-Format,格式化快捷键:shift + alt + f。
纯靠手动控制格式太麻烦了,还是使用工具吧
14.3 设计宏定义(Common.h)
显式将拷贝和移动函数删除,避免拷贝和移动操作:
1 |
新增 FLAG 标记,统一标记函数的返回:
1 | enum FLAG { |
记得修改包含的头文件。
14.4 重构Socket类
Socket 类主要是对 socket 操作进行了封装,并主要应用在 Acceptor 类中和 Connection 类中。对 Socket 类的函数进行重构,同时删去 InetAddress 类:
1 | class Socket { |
对于 Socket的创建、绑定、监听、接受等操作进行错误、异常的处理,在函数中大概如下:
1 | FLAG xxx() const { |
对于 Socket 的连接操作,是将 Socket 连接到某个 IP 地址,在函数中如下:
1 | FLAG Socket::socketConnect(const char *ip, uint16_t port) const { |
还有其他的 Get、Set 函数可详见代码。
14.4 小改Channel类和Epoll类
修改完 Socket 类后,比较底层的还有 Channel 类。Channel 类是网络库的核心组建之一,其对 socket 进行了更深度的封装,保存了需要对 socket 监听的事件和当前 socket 已经准备好的事件,并进行处理。此外,为了更新和获取在 epoll 中的状态,需要使用EventLoop进行管理。
对于 Channel 类的改动并不多,类声明如下:
1 | class Channel { |
大部分代码没什么特别的,可以见代码。但是需要注意的是,设置回调函数时,使用 std::move() :
1 | void Channel::setxxxCallback(std::function<void()> const &callback) |
Epoll 类主要是进行 IO 多路复用,保证高并发。在 Epoll 类主要是对 epoll 中 channel 的监听与处理。声明改为如下:
1 | class Epoll { |
函数方面也是小改。
14.5 小改EventLoop类
EventLoop 类用于对事件的轮询和处理。每一个 EventLoop 不断地调用 epoll_wait 来获取激活的事件,并处理。原本的 EventLoop 类中有一个普通的指针 Epoll*,现改为 std::unique_ptr。顺便再把函数声明为 const,使其更安全。
EventLoop 类声明如下:
1 | class EventLoop { |
由于使用了智能指针,所以其构造函数和析构函数也简化了不少。
14.6 小改Acceptor类
Acceptor 主要用于服务器接受连接,并在接受连接之后进行相应的处理。这个类需要独属于自己的 Channel,因此采用了智能指针管理。
Acceptor 类的重构类似。
- 将一些指针变成智能指针;
- 使用之前定义的
FLAG标记。
Acceptor 类声明如下:
1 | class Acceptor { |
14.7 小改Connection类
对于每个 TCP 连接,都可以使用一个类进行管理,在这个类中,将注意力转移到对客户端 socket 的读写上,除此之外,他还需要绑定几个回调函数,例如当接收到信息时,或者需要关闭时进行的操作。
对于 Connection 类中的指针改用智能指针,同时按需求简化了部分函数,声明如下:
1 | class Connection { |
14.8 重头戏Server类
Server 类是对整个服务器的管理,他通过创建 acceptor 来接收连接。并管理 Connection 的添加。
对 Server 类的众多指针都改为智能指针,声明如下:
1 | class Server { |
修改完这么多类后,记得查看代码修改一下测试的 server.cpp、SingleClient.cpp、MultipleClients.cpp 等文件,然后编译即可。
附录
附 1 - 代码运行环境
前十四章:
- 代码编写:Windows 下 Visual Studio 2022
- 代码编译及执行:阿里云 ECS,Ubuntu 20.04.6 LTS (GNU/Linux 5.4.0-169-generic x86_64)
在 Visual Studio 2022 中编写代码,接着连接远程服务器,将代码部署到服务器上。
- 前期在服务器使用
make编译代码。Ubuntu之make:make命令行工具的简介、安装、使用方法之详细攻略- 编译命令见每个 Day 中的 Makefile 文件。
make命令为:make build或make。- 清理编译结果命令为:
make clean。
- 若没有
make,可以手动输入(Makefile中的)g++命令编译。
- 编译命令见每个 Day 中的 Makefile 文件。
- 后期考虑使用 CMake 将项目工程化,详情看附录 2。
剩下章节:
- 代码编写:Windows 下 Visual Studio Code
- 代码编译及执行:WSL2 - Ubuntu 18.04
用 Visual Studio Code 远程连接 WSL 进行编写代码,使用 cmake 进行项目管理。
附 2 - CMake的安装和使用
此处的环境是:Visual Studio 2022 远程连接 Ubuntu 20.04.6 LTS
- 当然 Windows 也有 CMake,此处主要是在 Linux 下的使用。
附 2.1 检查远程的CMake环境和编译环境
可能需要先 apt-get update 更新一下 apt。
- 安装 CMake 工具
1 | apt-get install cmake |
- 可选择安装使用 clang 编译器
1 | apt-get install clang |
附 2.2 Visual Studio 2022中使用CMake进行远程Linux服务器开发
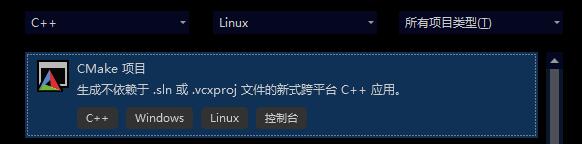
- 创建选择 CMake 项目,我此处构建演示项目
CMakeTestProject。
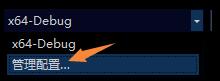
- 选择远程的 Linux 计算机,管理配置,新建一个配置。

- 编辑配置,具体看下图,主要修改部分已经框选。

-
正常编写代码,此处我用 Day12(第十二章)的代码作为演示。编写代码后,可以点进去根目录的
CMakeLists.txt文件,保存一下(ctrl + s),就会自动复制到远程。 -
进行项目生成和编译,项目生成有两种方式:
- 可以选择右键项目名,选择以 CMake 视图查看。再进行生成或清理,最后使用编译命令进行编译。
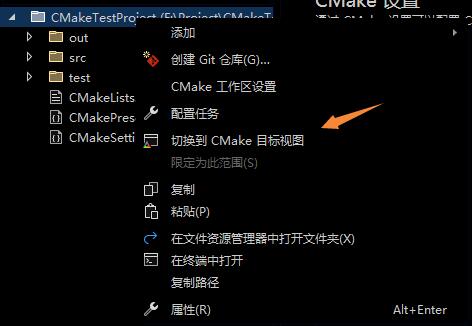
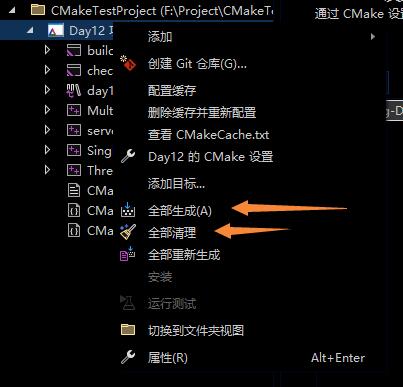

- 可以在 Linux 的终端上执行以下命令:
1 | mkdir build && cd build && cmake ../src/ && make |

可以在 CMakeLists.txt 中的项目信息之前设置编译器为Clang。
- 生成成功后就可以在
CMakeLists.txt中指定的输出文件夹中找到可执行文件或其他。
附 2.2 Visual Studio 2022中使用CMake进行WSL开发
有的人可能没有Linux服务器,但是WSL可以有的。如何安装WSL可以查看这里
基本步骤同上,但在新建配置和编辑时,需要做一些修改:

